Padrões de disponibilização de modelos
Inscreva-se na newsletter
Receba os novos tutoriais e faça parte da comunidade iafluente!
Muitos cientistas de dados gostam de utilizar notebooks Jupyter para treinar e interagir com modelos de machine learning (ML).
Apesar de convenientes durante a fase de experimentação, para utilizar ML como uma dentre muitas das peças de um sistema, a interação com os modelos precisa se dar de outra forma que não pelos notebooks.
Na prática, depois de treinados, os modelos são implantados em produção (deployed, em inglês). Esses modelos são então servidos para as aplicações, isto é, disponibilizados para que as aplicações possam utilizá-los.
Neste tutorial, vamos discutir os dois principais padrões de servir modelos de ML para aplicações: o padrão online e o em batch.
Exemplos de aplicações
Antes de entrar nos detalhes de cada um dos padrões, vamos descrever duas aplicações que utilizam ML. Ter esses exemplos em mente ajuda a entender o porquê de existirem padrões diferentes.
Aplicação 1: detecção de transações fraudulentas
Uma empresa provedora de cartões de crédito desenvolveu um modelo que detecta transações fraudulentas. Esse modelo é acionado toda vez que uma transação está sendo realizada, por exemplo quando uma pessoa paga sua conta em um restaurante utilizando a máquina de cartão de crédito. Espera-se que esse modelo classifique a transação como fraudulenta ou não em uma questão de instantes, para que consiga bloquear transações que julgue fraudulentas a tempo.
Aplicação 2: recomendação de filmes
Uma empresa de streaming desenvolve modelos de ML que fazem recomendações de filmes para seus usuários. Um usuário desse sistema não espera que suas recomendações sejam atualizadas várias vezes ao dia — na verdade, espera que as recomendações não mudem com tanta frequência, se não, vão parecer aleatórias. Por outro lado, é importante que as recomendações sejam atualizadas periodicamente, demonstrando que o sistema está constantemente aprendendo as preferências de seus usuários.
Você consegue pensar nas diferenças entre os dois sistemas do ponto de vista de ML?
Pense em:
- quantas vezes o modelo de ML é acionado em um dia típico;
- quantos dados o modelo processa cada vez que é acionado;
- consequências de uma falha no modelo;
- como os resultados de cada modelo seriam salvos e utilizados pela aplicação.
Note que apesar de ambas as aplicações usarem modelos de ML, a forma como esses modelos devem ser utilizados parece ser diferente para cada uma. Isso acontece porque as expectativas que cercam as aplicações são distintas e, naturalmente, as variáveis a serem otimizadas para cada uma delas mudam.
Vamos agora explorar os dois principais padrões de disponibilização de modelos para aplicações.
Padrão online
O padrão online é aquele em que o modelo está preparado para retornar suas predições instantes depois de ser acionado. Esse padrão também é conhecido como síncrono, porque a resposta do modelo está em sincronia com as requisições que ele recebe. As predições normalmente são feitas uma-a-uma e a variável que costuma ser mais importante é a latência.
A aplicação 1 (detecção de fraudes) é um exemplo típico que segue esse padrão. Assim que o usuário utiliza o seu cartão de crédito em um estabelecimento, os dados da transação são enviados para o modelo, o qual os processa e retorna a sua predição.
Na prática, no padrão online, o modelo geralmente é servido como uma API RESTful. A interação com o modelo se dá, então, por meio de requisições HTTP.
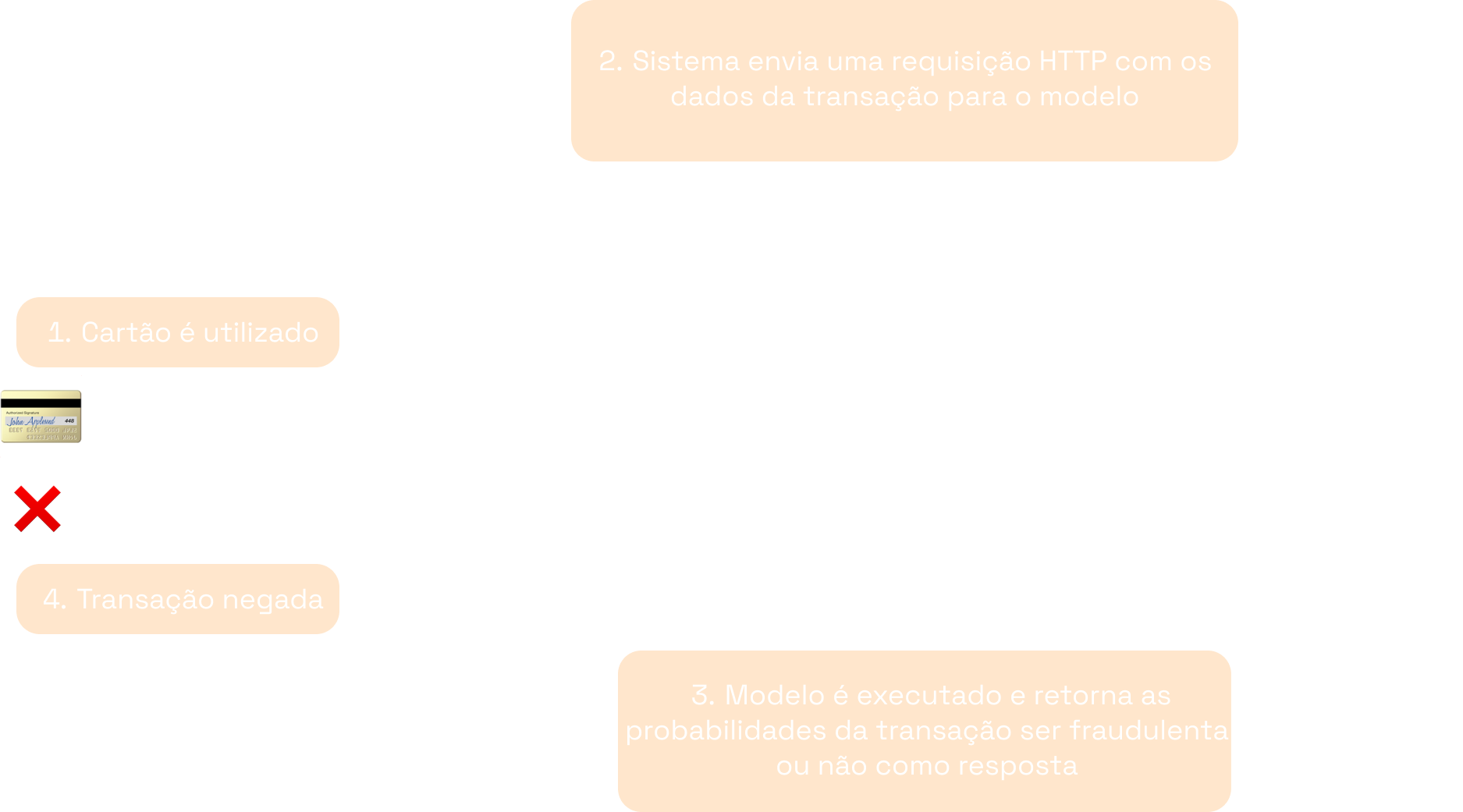
A imagem acima mostra, de forma simplificada, como o modelo de detecção de fraudes poderia ser disponibilizado na prática. O sistema de cartão de crédito pode enviar uma requisição para o endpoint do modelo com os dados da transação e receber as predições como resposta. Com base na resposta, o sistema então decide se permite ou nega a transação.
Em um tutorial futuro, discutiremos os detalhes de APIs RESTful e como criar APIs para os modelos. Por ora, você pode explorar algumas das ferramentas comumente utilizadas nesta etapa.
Algumas ferramentas que podem ser utilizadas para criar APIs para os modelos
- MLflow: ferramenta que serve para várias coisas, dentre elas, para servir modelos.
- BentoML: ferramenta focada na etapa de implantação de modelos. É possível escrever e configurar as APIs e pode ter desempenho melhor que MLflow.
- FastAPI e Flask: frameworks mais gerais utilizados para escrever APIs e que também podem ser utilizados para escrever as APIs de modelos.
Existem algumas vantagens de se ter o modelo disponível como uma API RESTful.
A primeira é que praticamente toda linguagem de programação tem bibliotecas para fazer requisições HTTP e processar as suas respostas. Dessa forma, não importa a linguagem utilizada na sua aplicação, ela conseguirá utilizar o modelo de ML. Por exemplo, em Python, a biblioteca mais utilizada é a requests.
A segunda vantagem é que é possível tirar proveito de toda maturidade dos provedores de soluções na nuvem (AWS, Google Cloud Platform, Microsoft Azure) para criar o endpoint do modelo. Utilizando esses provedores, é relativamente simples de preparar o endpoint do modelo para suportar milhares (a milhões) de requisições por segundo, utilizando autoscaling de forma eficiente.
Padrão em batch
O padrão em batch é aquele em que o modelo gera as predições para um conjunto de dados por vez (chamado de batch). Esses dados são acumulados e o modelo só é acionado quando determinado evento acontece. Nesse caso, a variável de interesse costuma ser o throughput.
A aplicação 2 (recomendação de filmes) é um exemplo típico que segue esse padrão. À medida que os usuários utilizam o sistema, os dados das suas preferências são acumulados. O modelo, então, é acionado periodicamente para atualizar suas recomendações.
Enquanto no padrão online o modelo costuma ser servido como uma API RESTful, no padrão em batch é comum existir um script de predição. Esse script é responsável por puxar os dados a serem utilizados — de um banco de dados, por exemplo —, carregar e executar o modelo, e salvar suas predições — novamente em um banco de dados, por exemplo. Por sua vez, a execução do script é disparada por um evento: seja um sinal que a aplicação envie, seja um horário do dia, ou algum outro gatilho.
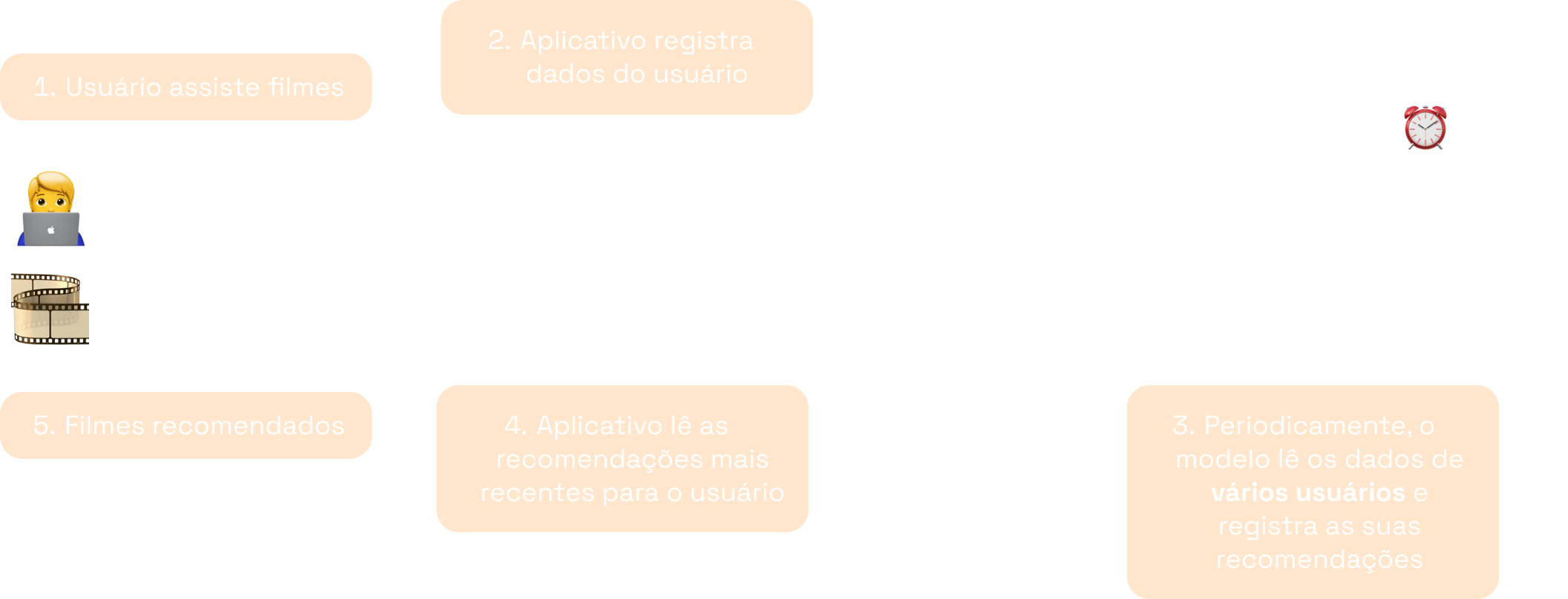
No exemplo da aplicação de streaming, o script de predição poderia ser programado para ser executado algumas vezes ao dia. A cada vez, ele puxaria os dados de uma fração de usuários e atualizaria suas recomendações de uma vez só.
O padrão batch é apropriado para situações em que é necessário utilizar o modelo para processar um grande volume de dados e não há expectativa de que as predições estejam disponíveis instantaneamente. Nesses cenários, é possível de beneficiar-se das tecnologias de computação distribuída.
O trabalho de predição de modelos de ML é facilmente paralelizável. Afinal, a predição para cada dado é independente das demais. Dessa forma, em vez de executar o script de predição em uma única máquina, é possível dividir os dados, processar cada fração em uma máquina diferente e agrupar as predições no final.
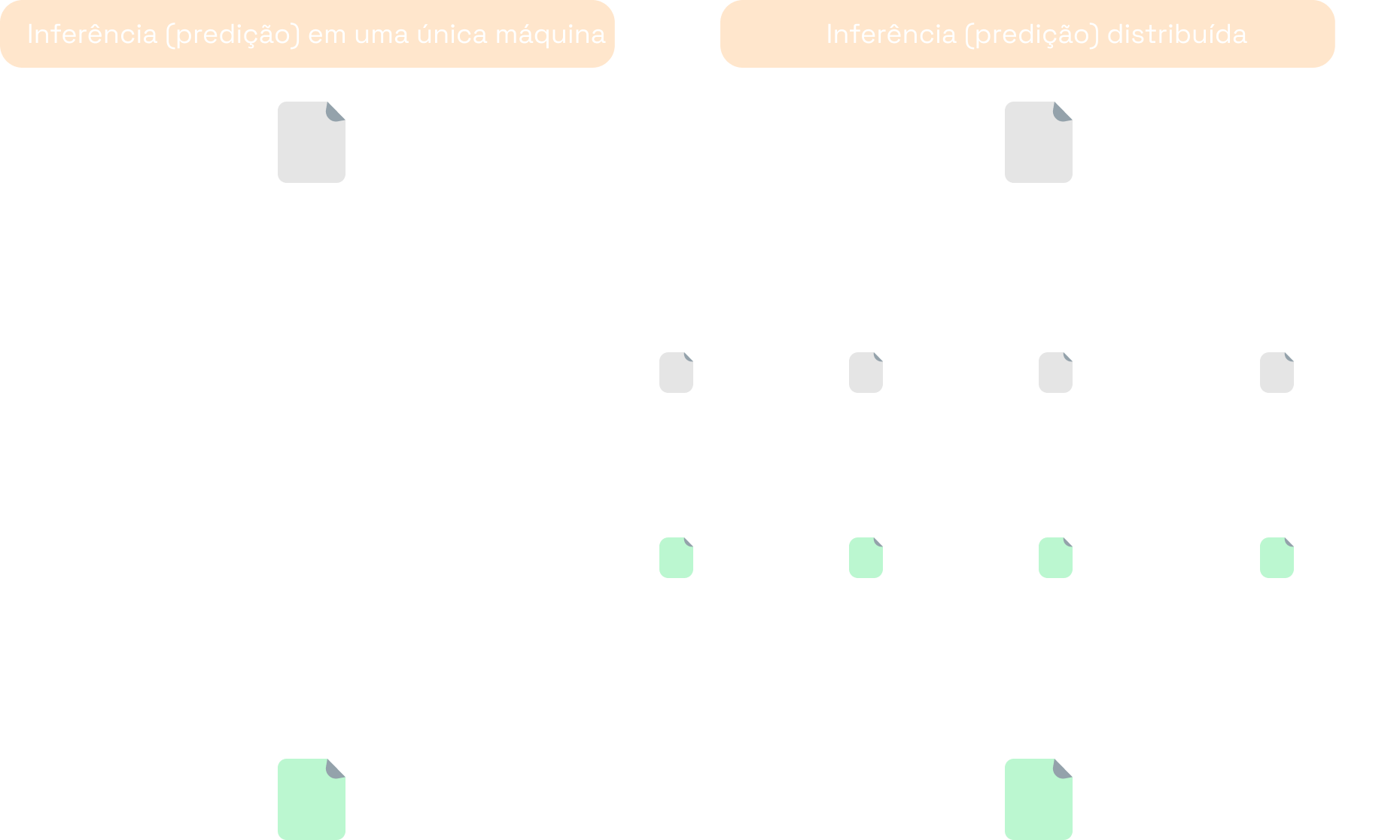
Na prática, não é preciso se preocupar com os vários detalhes envolvidos em inicializar as máquinas, dividir os dados, coordenar os trabalhos de predição etc. Existem tecnologias maduras que já fazem todo o trabalho pesado por trás das cortinas. Basta escrever o script na linguagem adequada e executá-lo na infraestrutura correta.
Se você está interessado(a) em utilizar computação distribuída
Algumas das tecnologias frequentemente citadas são Spark e Hadoop MapReduce. Em geral, essas tecnologias são utilizadas por meio de provedores de soluções na nuvem, como AWS EMR, Google Cloud Dataproc, Azure HDInsight e Databricks.