Introdução a RAG
Inscreva-se na newsletter
Receba os novos tutoriais e faça parte da comunidade iafluente!
Os large language models (LLM) são treinados em bases de dados que englobam boa parte da internet. Consequentemente, eles adquirem o que aparenta ser uma capacidade analítica fundamentada em conhecimentos gerais dos mais diversos assuntos.
O sucesso de aplicativos como o ChatGPT é prova que essa visão genérica de mundo pode ser muito útil. Porém, existem 3 grandes limitações que devem ser superadas se você está pensando em construir um sistema que utilize um LLM:
-
Os LLMs possuem um conhecimento geral, mas eles não conhecem os seus dados. Dessa forma, a pergunta que surge é: se ele não tem ciência dos seus dados, como que um LLM pode ajudar no seu problema específico ou no problema dos seus usuários?
-
Os LLMs sempre vão produzir alguma resposta, independentemente da instrução dada. Todavia, nem sempre essa resposta é factualmente correta.
-
Existe um cut off temporal nos dados de treinamento dos LLMs. Por exemplo, existem LLMs que só foram treinados em dados até 2023. Isso significa que o modelo só tem conhecimento dos fatos ocorridos até a data limite e não sabem de nada mais recente.
Alguns dos pontos acima podem ser mais ou menos relevantes a depender da sua aplicação. O fato é que você provavelmente terá que lidar com pelo menos um deles na sua jornada para resolver problemas reais com LLMs.
Uma das técnicas que vem tendo sucesso na prática para mitigar as limitações levantadas é o RAG (retrieval augmented generation). Neste tutorial, vamos explorar o que é RAG, construir um protótipo de sistema usando RAG e discutir como essa técnica se compara a outras, como prompt engineering e fine-tuning.
O que é RAG?
A forma padrão de utilizar LLMs consiste em dar ao modelo uma instrução (chamada prompt) e receber de volta uma resposta gerada. Esse processo, que possui uma única etapa, é ilustrado na figura abaixo.

RAG é uma das técnicas que podem ser utilizadas para contornar as limitações mencionadas na introdução. Com RAG, o modelo não é modificado. Em vez disso, a instrução é primeiro enriquecida com contexto adicional antes ser enviada ao modelo. Dessa forma, o LLM não precisa se basear somente em seu conhecimento genérico. Ele também pode utilizar o contexto fornecido para gerar sua resposta.
O acrônimo RAG faz alusão às etapas envolvidas na técnica: retrieval (recuperação do contexto relevante para a instrução) augmented (enriquecimento da instrução original com o contexto recuperado) generation (geração da resposta pelo LLM).
Você entende como usar RAG minimiza os três problemas levantados na introdução?
-
Conhecimento dos seus dados. Os seus dados relevantes para a instrução podem ser injetados como parte do contexto. Dessa forma, apesar do LLM não ter sido treinado nos seus dados, ele pode se basear neles para produzir a resposta.
-
Alucinação. A resposta do modelo tende a ser "ancorada" no contexto recuperado, mitigando o problema de alucinações. É claro que elas ainda podem acontecer, por exemplo, se o modelo ignorar a instrução de se basear nos fatos recuperados.
-
Cut off temporal. Em vez de se basear apenas no conhecimento do modelo até o cut off, você pode recuperar informações mais recentes e pedir para o modelo utilizá-las para gerar a resposta.
Graças a ferramentas como LlamaIndex, LangChain, chroma, e outras, está cada vez mais fácil criar sistemas RAG. Porém, sair de um protótipo para um sistema em produção ainda está longe de ser trivial.
Criando um sistema RAG: passo-a-passo
Como vimos na seção anterior, um sistema que utiliza RAG possui algumas peças diferentes que devem ser conectadas.
Nesta seção, vamos construir o protótipo de um sistema que responde perguntas sobre os tutoriais do iafluente utilizando RAG. A ideia é construir um aplicativo parecido com o ChatGPT, mas que consiga responder perguntas específicas sobre os tutoriais do iafluente, como no exemplo abaixo.
Repositório no GitHub
O código completo do protótipo que vamos construir está disponível no GitHub.
Vamos passar por cada um dos componentes envolvidos em uma sequência que faz sentido lógico. Além disso, vamos discutir os princípios e trade-offs envolvidos em cada etapa.
Note que sem RAG, seria difícil de construir essa aplicação. O iafluente (ainda!) não é grande o suficiente e provavelmente não faz parte da base de dados de treinamento de modelos como o GPT. Mesmo que fizesse, o iafluente seria uma fração tão pequena da base de dados que o modelo
provavelmente não seria capaz de responder perguntas específicas sobre ele.
Indexação e recuperação
Um dos principais componentes necessários para se ter um bom sistema RAG é a base de dados com os contextos. A etapa responsável pela construção dessa base de dados é chamada indexação.
O primeiro passo para a indexação é obter todos esses dados, limpá-los e padronizá-los, já que eles potencialmente estão em diversos formatos (como PDF, HTML, MarkDown).
No nosso caso, os dados que serão indexados são os tutoriais do iafluente, como o Padrões de disponibilização de modelos, Modelos baseline, entre outros. Esses tutoriais, disponíveis nos links anteriores, são páginas HTML. Vamos baixar essas páginas, processá-las para extrair o
seu conteúdo e colocá-los em um único arquivo txt.
Para economizar tempo e focarmos somente no que importa para este tutorial, você pode baixar o arquivo txt neste link ou executando:
Notebook no Google Colab
O código para a indexação está neste notebook, que você pode abrir no Google Colab ou executar localmente.
curl -L -o "iafluente.txt" "https://raw.githubusercontent.com/gustavocidornelas/rag-iafluente/refs/heads/main/data/iafluente.txt"
Você pode ler o aquivo e separar os tutoriais com:
# Lendo o arquivo
with open("./iafluente.txt", "r") as file:
data = file.read()
# Cada post está separado por "%%%", então para obter uma lista de posts, basta:
posts = data.split("%%%")
# Conferindo os primeiros 500 caracteres do primeiro post
posts[0][:500]
Agora, nós temos uma lista (posts) com cada um dos posts que podem ser relevantes para responder perguntas sobre o iafluente. Porém, para que o nosso sistema seja útil, é fundamental saber qual desses tutoriais utilizar como contexto para uma dada pergunta.
Por exemplo, se a pergunta recebida é “como posso utilizar computação distribuída para disponibilizar meus modelos de ML?”, o tutorial que possui a resposta para essa pergunta é o Padrões de disponibilização de modelos de ML e não o Código para produção.
Encontrar o contexto relevante para uma dada pergunta é o papel do sistema de recuperação (o retriever na figura na seção anterior).
Por que não é uma boa ideia fornecer todo o arquivo txt para o LLM o tempo todo?
Talvez você esteja pensando: "já que as respostas para as perguntas do usuário devem estar em algum lugar no arquivo txt, por que não fornecer o arquivo inteiro como contexto para o LLM?".
Essa é uma dúvida pertinente. Em princípio, o LLM poderia ler o conteúdo do arquivo inteiro e retornar uma resposta. Porém, existem alguns motivos que tornam essa abordagem uma má prática.
O primeiro é que os LLMs têm um limite de tokens que podem ser fornecidos como entrada. Esse limite geralmente é conhecido como context lenght ou context window. Para o GPT-3, o limite era de 2048 tokens, para o GPT-4, o limite é 8192 tokens. No nosso caso, como os posts são relativamente curtos, não vamos chegar perto desse limite. Porém, se você estiver lidando com documentos mais longos, é possível que você encontre esse problema.
A tendência é que os modelos futuros tenham limites cada vez maiores. O Google, por exemplo, anunciou que o seu modelo Gemini tem um limite de 1 milhão de tokens.
Mesmo assim, não é uma boa ideia fornecer textos longos demais como contexto, o que nos leva ao segundo motivo: quanto mais informação você fornecer ao modelo, mais difícil será para ele encontrar os trechos relevantes para responder à pergunta. Se você conseguir, de alguma forma, filtrar o contexto para que ele seja mais relevante, é uma boa ideia fazê-la. Existem alguns resultados de pesquisa que mostram que quando muita informação é fornecida ao modelo, ele pode "deixar passar" informações relevantes. Esse problema é conhecido como lost in the middle e é analizado neste artigo.
O terceiro motivo para fornecer um contexto menor tem a ver com os aspectos práticos do sistema. Quanto maior o contexto, mais tempo o modelo vai levar para processá-lo. Se você está construindo um sistema que precisa responder rapidamente, é uma boa ideia fornecer o menor contexto possível. Esse é um dos motivos que muitas pessoas acreditam que RAG continuará sendo relevante mesmo quando o context length dos LLMs for muito grande. Para grande parte das aplicações, a latência será uma métrica importante, então faz sentido limitar o contexto fornecido aos modelos. Além disso, o custo de utilizar LLMs costuma ser diretamente proporcional ao número de tokens fornecidos como entrada, então contextos menores também são mais baratos.
Talvez você esteja se perguntando como o retriever consegue saber o que é relevante. Normalmente, os contextos não são
armazenados somente como texto, como no nosso arquivo txt. Em vez disso, eles também são armazenados como vetores, chamados embeddings.
Esses vetores são armazenados em um banco de dados de vetores (como Pinecone, chroma, ou até mesmo o Postgres). O retriever então transforma a pergunta do usuário em um embedding e recupera os contextos mais similares do banco de vetores utilizando alguma métrica de similaridade de vetores (como a similaridade por cosseno).
O que são embeddings?
A grosso modo, embeddings são representações vetoriais para textos. É importante representar textos como vetores porque praticamente todos os modelos de machine learning trabalham com vetores.
Embeddings é um tópico fascinante e eu recomendo essa referência mais detalhada sobre o assunto ou este post que eu escrevi anteriormente sobre o tema.
Vamos agora criar um banco de dados de vetores com os embeddings dos tutoriais do iafluente usando
a biblioteca chromadb.
O primeiro passo é instalar a biblioteca no seu ambiente.
Agora, vamos criar o banco de dados de vetores. No chromadb, o banco é chamado collection e, para utilizá-lo, precisamos salvá-lo. Você pode fazer isso com:
import chromadb
# Vamos salvar o banco de dados de vetores em '../app/model/context'
client = chromadb.PersistentClient(path="../app/model/context")
# Criar o banco de vetores, com o nome 'context'
collection = client.get_or_create_collection(name="context")
Após executar o código acima, você deve ver um arquivo chamado chroma.sqlite3 no diretório app/model/context. Esse arquivo é o banco de vetores que vamos utilizar para recuperar o contexto relevante para uma pergunta.
Por enquanto, o banco está vazio. Vamos preenchê-lo com os vetores dos tutoriais do iafluente. Para isso, vamos utilizar a função add do collection que criamos anteriormente.
# Adicionando os posts ao banco de dados
collection.add(
documents=posts,
ids=[str(i) for i in range(len(posts))]
)
Com o banco de vetores pronto, podemos usar perguntas para consultar o banco e verificar se o contexto retornado faz sentido. A função query do collection é responsável por isso.
collection.query(
query_texts=["Como posso utilizar computação distribuída para disponibilizar meus modelos de ML?"], # Essa pergunta vai ser embedded e comparada com os embeddings dos posts
n_results=1 # Quantos resultados queremos. No caso, só queremos o mais similar
)
# Output:
# {
# 'ids': [['3']],
# 'distances': [[0.58284265256851]],
# 'metadatas': [[None]],
# 'embeddings': None,
# 'documents': [['\n\n---\ntitle: Padrões de disponibilização de modelos de ML...]],
# 'uris': None,
# 'data': None,
# 'included': ['metadatas', 'documents', 'distances']
# }
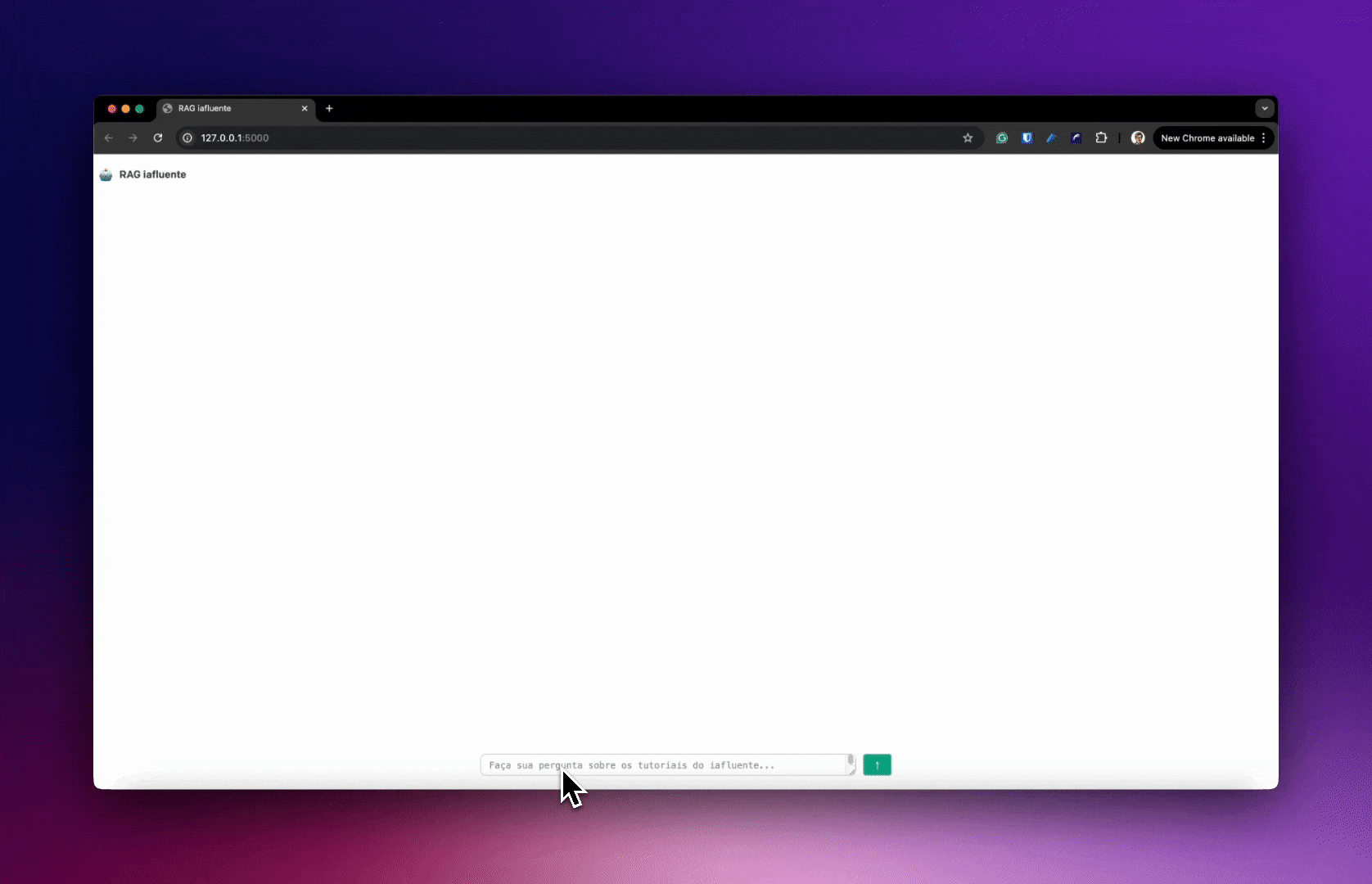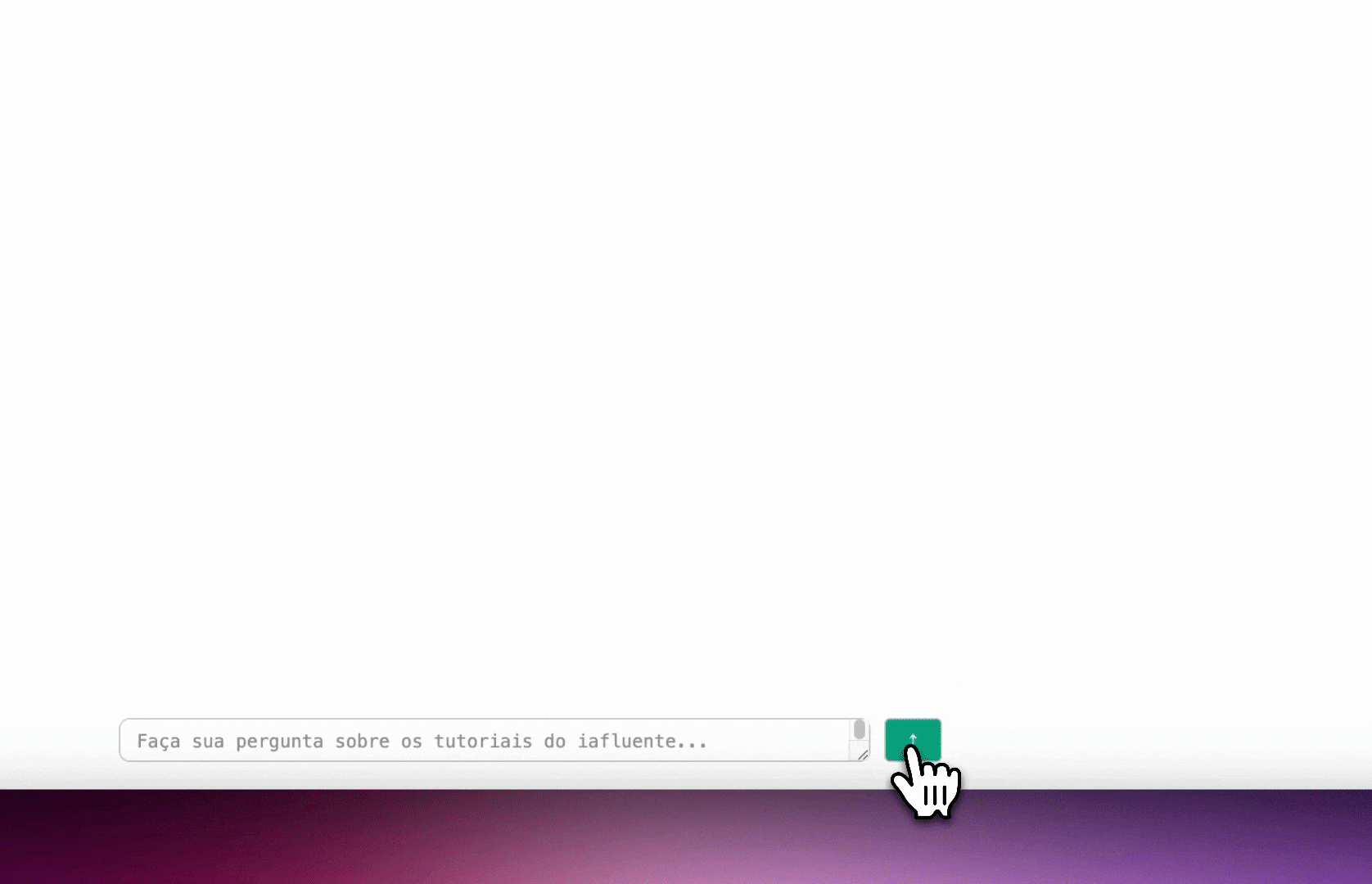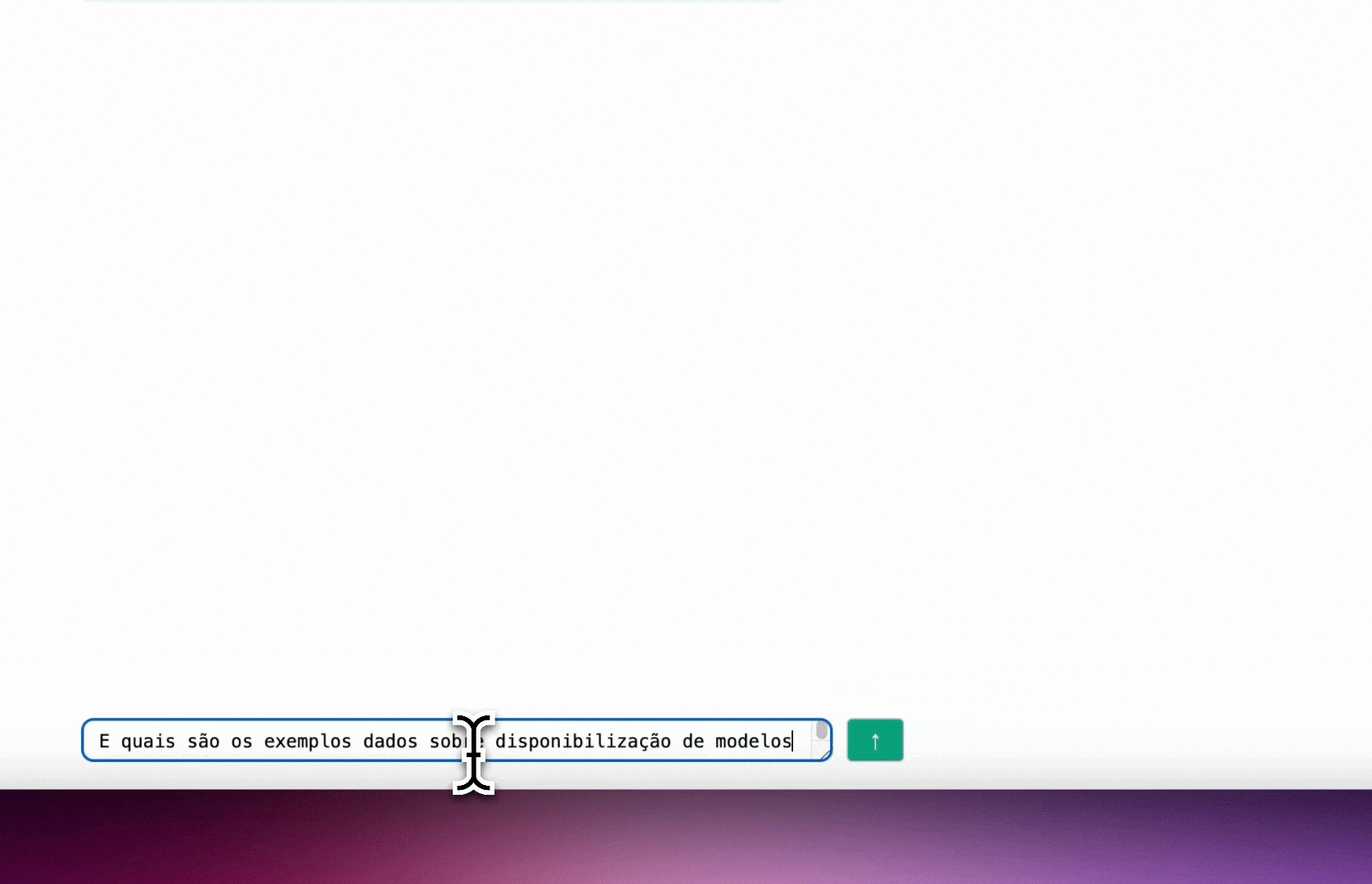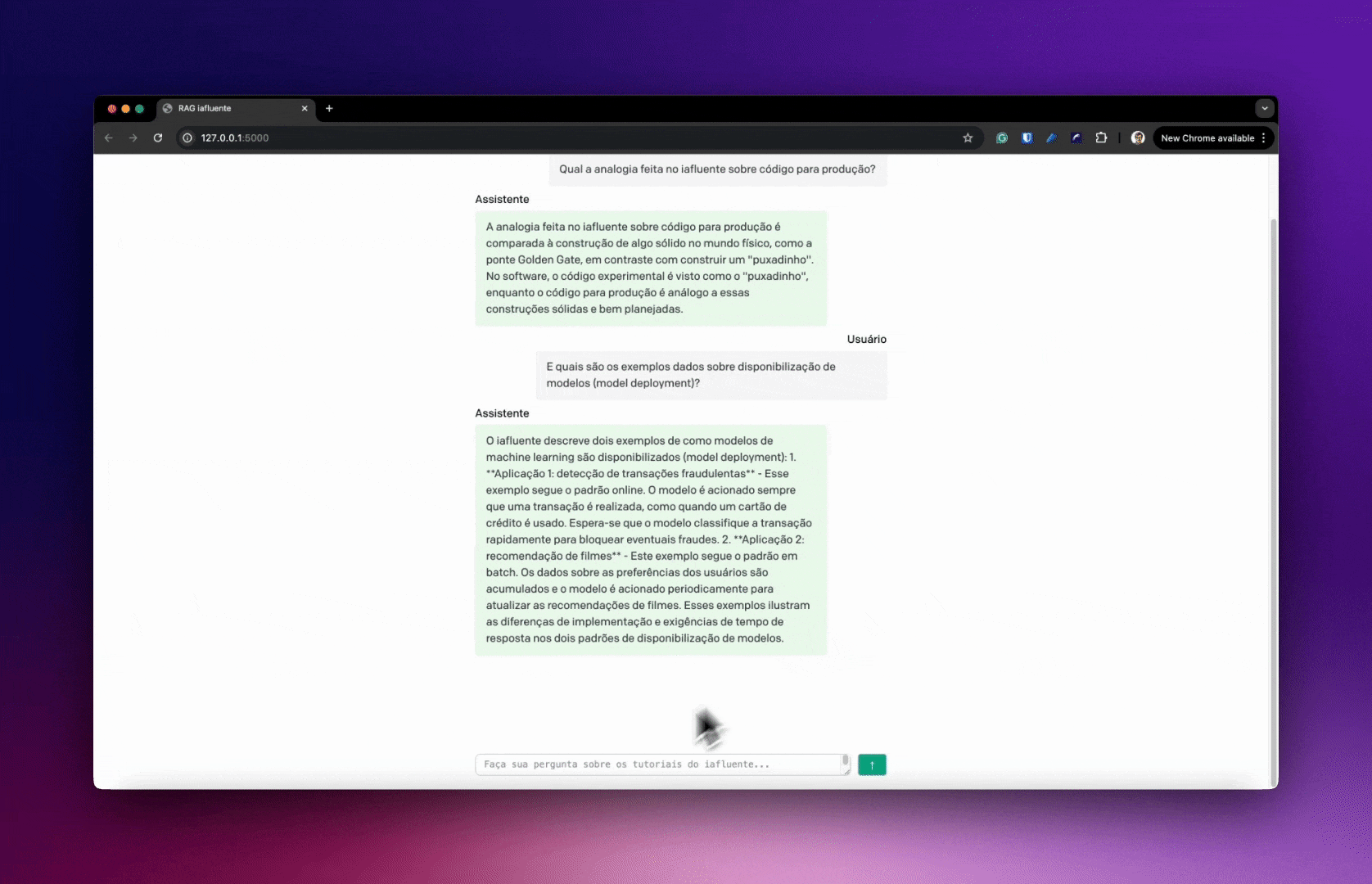
O post retornado está correto! Podemos também fazer perguntas bem específicas, como sobre uma analogia feita em um dos tutoriais:
collection.query(
query_texts=["Qual é a analogia feita no iafluente entre código e construção civil?"],
n_results=1
)
# Output:
# {
# 'ids': [['1']],
# 'distances': [[0.9849246153380313]],
# 'metadatas': [[None]],
# 'embeddings': None,
# 'documents': [['\n\n---\ntitle: Código para produção...]],
# 'uris': None,
# 'data': None,
# 'included': ['metadatas', 'documents', 'distances']
# }
Já temos uma forma de recuperar o contexto relevante para uma pergunta. Agora, vamos ver como podemos utilizar esse contexto para produzir uma resposta com o LLM.
LLM
Convencionalmente, o que se faz para juntar os contextos com a pergunta do usuário é utilizar um template de prompt. O template possui um espaço para inserir a pergunta do usuário e outro para inserir o contexto recuperado. O template instrui o modelo a utilizar o contexto recuperado para gerar a resposta. O template pode ser algo como:
Você é um assistente que responde perguntas sobre o iafluente,
um site educativo com tutoriais sobre inteligência artificial (IA).
Você deve responder à pergunta do usuário utilizando apenas o contexto
fornecido. Caso o contexto não seja relevante para responder à pergunta,
responda com "O iafluente não tem a resposta para essa pergunta.".
Pergunta:
{{ question }}
Contexto:
{{ context }}
Em que {{ question }} e {{ context }} são preenchidos com a pergunta do usuário e o contexto recuperado, respectivamente.
Agora, para gerar a resposta, basta preencher o template e passá-la para o LLM. Vamos utilizar o modelo GPT-4o da OpenAI, mas você poderia substituir por qualquer outro modelo que você tenha acesso.
import openai
openai_client = openai.OpenAI(api_key="SUA_API_KEY_DA_OPENAI")
def generate_answer(question: str, context: str) -> str:
# Preenchendo o template de prompt
prompt = f"""
Você é um assistente que responde perguntas sobre o iafluente,
um site educativo com tutoriais sobre inteligência artificial (IA).
Você deve responder à pergunta do usuário utilizando apenas o contexto
fornecido. Caso o contexto não seja relevante para responder à pergunta,
responda com "O iafluente não tem a resposta para essa pergunta.".
Pergunta:
{question}
Contexto:
{context}
"""
# Gerando a resposta com o GPT-4o
response = openai_client.chat.completions.create(
messages=[
{"role": "user", "content": prompt},
],
model="gpt-4o",
)
return response.choices[0].message.content
Juntando as peças
Nas seções anteriores, construímos todos os componentes necessários para responder perguntas sobre os tutoriais do iafluente. Agora, vamos juntar todos esses componentes em uma única função que recebe a pergunta do usuário e retorna a resposta. Essa função é o nosso sistema RAG e implementa o diagrama que vimos anteriormente.
Vamos criar uma classe chamada RagPipeline que encapsula toda a lógica do sistema RAG. O principal método dessa classe é o answer, que recebe a pergunta do usuário e retorna a resposta.
"""Arquivo `app/model/rag.py` no repositório. Modulo com a pipeline RAG. """
import os
import chromadb
import openai
from openai.types.chat.chat_completion import ChatCompletion
CONTEXT_PATH = os.path.join(os.path.dirname(__file__), "context")
class RagPipeline:
"""Pipeline RAG.
O método principal é o `answer`, que responde à pergunta do usuário com
o LLM.
"""
def __init__(self):
self.openai_client = openai.OpenAI()
chroma_client = chromadb.PersistentClient(path=CONTEXT_PATH)
self.collection = chroma_client.get_collection(name="context")
def answer(self, question: str, stream: bool = False) -> ChatCompletion:
"""Método principal.
Implementa cada uma das etapas do RAG.
"""
context = self.retrieve_context(question)
prompt = self.prepare_prompt(question, context)
answer = self.generate_answer(prompt, stream)
return answer
def retrieve_context(self, question: str) -> str:
"""Retriever de contexto.
Dada uma pergunta (`question`), retorna o contexto mais similar
do banco de vetores.
"""
return self.collection.query(query_texts=[question], n_results=1)["documents"][
0
]
def prepare_prompt(self, question: str, context: str) -> str:
"""Combina a pergunta do usuário com o contexto recuperado,
preenchendo o template de prompt.
"""
prompt = f"""
Você é um assistente que responde perguntas sobre o iafluente,
um site educativo com tutoriais sobre inteligência artificial (IA).
Você deve responder à pergunta do usuário utilizando apenas o contexto
fornecido. Caso o contexto não seja relevante para responder à pergunta,
responda com "O iafluente não tem a resposta para essa pergunta.".
Pergunta:
{question}
Contexto:
{context}
"""
return prompt
def generate_answer(self, prompt: str, stream: bool) -> ChatCompletion:
"""Envia a instrução ao LLM e retorna a resposta."""
response = self.openai_client.chat.completions.create(
messages=[{"role": "user", "content": prompt}],
model="gpt-4o",
stream=stream,
)
return response
Pronto! Temos um sistema de RAG completo:
- O usuário faz uma pergunta relacionada ao
iafluente. - A pergunta é transformada em um embedding (por trás das cenas, no método
retrieve_context). - O retriever compara o embedding da pergunta com os embeddings dos tutoriais do
iafluentesalvos no banco de vetores e retorna o contexto mais relevante (por trás das cenas, no métodoretrieve_context). - A pergunta do usuário e o contexto recuperado são injetados no template de prompt (método
prepare_prompt). - O LLM gera a resposta utilizando o prompt preenchido e a resposta é retornada ao usuário (método
generate_answer).
Para usar o sistema, é só instanciar a classe RagPipeline e chamar o método answer com a pergunta do usuário.
rag = RagPipeline()
question = "Como posso utilizar computação distribuída para disponibilizar meus modelos de ML?"
answer = rag.answer(question)
print(answer)
Próximos passos
Limitações do protótipo
No início do tutorial, mencionei que a cada dia que passa, fica mais fácil construir um protótipo de um sistema RAG. Nós mesmos acabamos de construir um em alguns minutos. Porém, esse protótipo possui algumas limitações, que o fazem um protótipo e não um produto robusto.
A primeira delas é que o nosso retriever sempre retorna um único tutorial como contexto. Isso significa que o nosso sistema só consegue responder perguntas cujas respostas estejam contidas em um único tutorial. Se a pergunta do usuário for sobre um tópico que está em mais de um tutorial, o nosso sistema não consegue respondê-la adequadamente.
A quantidade de tutoriais retornados é controlada pelo parâmetro n_results na função query, no nosso método retrieve_context. Poderíamos aumentar o valor de n_results, mas isso só aumentaria um segundo problema: a maior parte do contexto recuperado não é relevante para responder à pergunta do usuário.
Um tutorial possui muitas informações. Algumas são relevantes para responder à pergunta, outras não. O ideal seria que o retriever retornasse apenas os trechos mais relevantes para responder à pergunta. Assim, o LLM ficaria focado e seria mais provável que a resposta fosse correta.
Chunking e re-ranqueamento
Para contornar essas limitações, o que costuma ser feito na prática é criar um banco de vetores não com os tutoriais completos, mas sim com diferentes trechos dos tutoriais. O retriever então, retorna uma lista de trechos relevantes para a pergunta do usuário. Por isso, no diagrama de bloco do RAG que vimos anteriormente, escrevi que o output do retriever são os top k contextos — isto é, os k trechos mais relevantes para responder à pergunta (onde k é um valor definido na construção do sistema, por exemplo, 5). Esses trechos costumam ser chamados de chunks.
Um retriever que retorna chunks em vez de posts completos é parte de uma solução mais robusta. Além disso, existem formas de melhorar o retriever, seja utilizando métricas diferentes da similaridade por cosseno, seja utilizando embeddings melhores, ou re-ranqueando os chunks retornados do banco de vetores. Esses são tópicos que podemos explorar em tutoriais futuros.
Você consegue notar alguma semelhança entre o retriever e uma classe de modelos clássicos de machine learning?
Os retrievers são muito semelhantes aos modelos de ranking em ML. O objetivo dos dois sistemas é identificar e ranquear uma lista de itens conforme sua relevância para uma dada pergunta. Por isso, muitas pessoas utilizam técnicas de ranking clássicas para avaliar e melhorar os retrievers.
Avaliação
Apesar do amplo espaço para melhoria do sistema, diria que o principal ponto que não tocamos neste tutorial foi a avaliação do sistema. Atualmente, não é possível saber se o sistema está indo bem ou mal. Se há padrões de falha consistentes, se as respostas do sistema são satisfatórias ou se, mesmo com os contextos, o sistema está alucinando.
Um bom processo de avaliação é uma das peças-chave que diferencia um protótipo que parece funcionar bem de um sistema sério, utilizado em escala. No futuro, vamos explorar como avaliar sistemas RAG e como melhorá-los a partir dessas avaliações utilizando ferramentas como Openlayer.
Prompt engineering x RAG x Fine-tuning
A última pergunta que gostaria de responder é: como RAG se compara a outras técnicas, como prompt engineering e fine-tuning?
Prompt engineering é a forma mais básica de fazer LLMs trabalharem da forma como você quer. A ideia é experimentar instruções diferentes, buscando chegar cada vez mais perto de uma instrução clara, que faça o modelo gerar a resposta desejada.
Em geral, quando você pensa em resolver um problema com LLMs, prompt engineering é a primeira técnica que você deve tentar. Você pode manualmente copiar e colar trechos que possam ser relevantes para a resposta e usar ferramentas que auxiliem na criação de prompts. Por exemplo, a Anthropic, possui uma ferramenta que auxilia na geração de prompts.
Boas práticas para prompts
A maior parte dos provedores de LLMs fornecem guias com boas práticas de prompt para os seus modelos. Esse é o da OpenAI, esse o da Anthropic, esse é o dos modelos Llama, da Meta.
A maior limitação de prompt engineering é que, no final do dia, você está limitado ao conhecimento que o modelo já possui. Se o modelo não tem conhecimento sobre o seu domínio, não importa o quão bom seja o seu prompt, ele não vai ser suficiente para o LLM fazer o que você quer.
Por outro lado, prompt engineering sempre é um componente importante do sistema, mesmo que você utilize RAG ou fine-tuning, já que você sempre vai precisar interagir com o LLM.
Se você parar para pensar, RAG é praticamente uma forma de prompt engineering. Em vez de criar um prompt manualmente, você cria um sistema que constrói o prompt automaticamente: uma combinação do template, da pergunta do usuário e do contexto recuperado, como vimos nas seções anteriores.
Tanto prompt engineering quanto RAG são técnicas que não modificam o LLM. Ambas se beneficiam do fato de LLMs serem ótimos em aprender algo novo a partir da instrução dada (chamada in-context learning). Porém, em alguns casos, uma boa instrução pode não ser suficiente.
É nesse cenário que entra o fine-tuning. Com fine-tuning o LLM é modificado. O ponto de partida é um modelo já treinado, como o GPT. Então, são feitas algumas iterações de treinamento com um conjunto de dados específico para o seu problema. Assim, o modelo é ajustado para responder melhor às perguntas do seu domínio.
Existem diversas formas de adaptar o modelo para o seu domínio com fine-tuning: desde ajustar apenas parte dos parâmetros do modelo ou usando um "adaptador" (como LoRA).
Fine-tuning é um tópico extenso além do escopo deste tutorial. Por hora, basta saber como ela se compara a RAG e prompt engineering e reconhecer que existem complexidades adicionais envolvidas em fine-tuning que não estão presentes nas outras técnicas. Por exemplo, a coleta de dados para "re-treinar" o modelo, a complexidade técnica de treinar e servir um modelo, entre outras.
| Prompt engineering | RAG | Fine-tuning | ||
|---|---|---|---|---|
| Modifica o LLM | Não. | Não. | Sim. | |
| Limitado aos conhecimentos do LLM | Sim. | Não, tirando proveito da capacidade do LLM de aprender com o contexto (in-context learning). | Não, ensinando o LLM durante processo de fine-tuning. | |
| Maior desafio | Experimentar com diferentes instruções. | Criar um bom retriever. | Complexidades associadas ao treinamento e disponibilização do LLM. |